
İçindekiler
- 1 ChatGPT’nin Eğitimi Nasıl Gerçekleşti?
- 1.0.1 1. Dev Metin Veri Kümeleriyle Başlangıç (Ön Eğitim)
- 1.0.2 2. Kendi Kendine Öğrenme (Unsupervised Learning)
- 1.0.3 3. İnsan Geri Bildirimleriyle Öğrenme (Reinforcement Learning from Human Feedback – RLHF)
- 1.0.4 4. Ödül Modelinin Oluşturulması
- 1.0.5 5. Pekiştirmeli Öğrenme ile İyileştirme
- 1.0.6 6. Diyalog Odaklı Eğitim
- 1.0.7 7. Güvenlik ve Ahlaki Filtreleme
- 1.0.8 8. Farklı Dillerdeki Verilerle Çok Dillilik
- 1.0.9 9. Sürekli İyileştirme ve Güncelleme
- 1.0.10 10. Parametre Sayısının Büyüklüğü
ChatGPT’nin Eğitimi Nasıl Gerçekleşti?
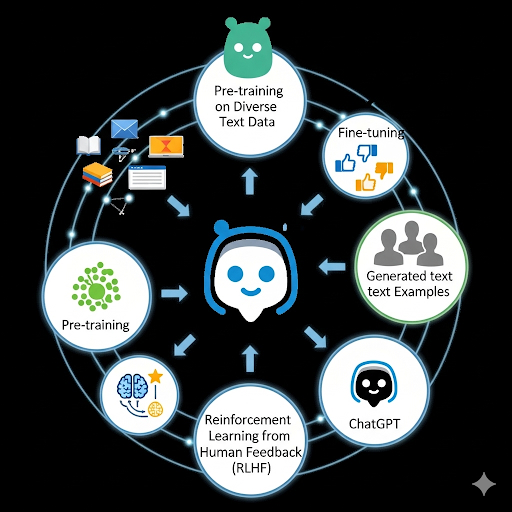
ChatGPT, OpenAI tarafından geliştirilen büyük bir dil modeli olarak, insan benzeri metinler üretebilme yeteneğiyle dikkat çekiyor. Ancak bu yeteneğin arkasında, karmaşık ve çok aşamalı bir eğitim süreci yatıyor. ChatGPT’nin nasıl bu kadar yetenekli hale geldiğini anlamak için, onun eğitim yolculuğunu detaylı bir şekilde incelemek gerekir. İşte ChatGPT’nin eğitimi hakkında 10 ana başlık.
1. Dev Metin Veri Kümeleriyle Başlangıç (Ön Eğitim)
ChatGPT’nin eğitimi, internet üzerindeki milyarlarca kelimeden oluşan devasa metin veri kümeleriyle başladı. Bu veri setleri, web siteleri, kitaplar, makaleler, Wikipedia ve diğer dijital metin kaynaklarını içeriyor. Model, bu veri kümelerini okuyarak dilin gramerini, sözdizimini, farklı konular arasındaki ilişkileri ve genel dünya bilgisini öğrendi. Bu aşama, modelin adeta bir ansiklopediye dönüşmesini sağlayarak, gelecekteki görevleri için sağlam bir temel oluşturdu.
2. Kendi Kendine Öğrenme (Unsupervised Learning)
Model, ön eğitim aşamasında “kendi kendine öğrenme” (unsupervised learning) metodunu kullandı. Bu, bir insan tarafından etiketlenmiş verilere ihtiyaç duymadan, bir sonraki kelimenin ne olacağını tahmin etme göreviyle gerçekleşti. Örneğin, “Kediler fareleri…” cümlesinden sonra “yakalar” kelimesinin gelebileceğini öğrendi. Bu süreç, modelin dili kendi kendine anlamasına ve mantıksal bağlantılar kurmasına olanak tanıyarak, temel dil becerilerini geliştirmesini sağladı.
3. İnsan Geri Bildirimleriyle Öğrenme (Reinforcement Learning from Human Feedback – RLHF)
ChatGPT’nin en kritik aşamalarından biri, “İnsan Geri Bildirimleriyle Pekiştirmeli Öğrenme” (RLHF) tekniğidir. Bu aşamada, insan denetçiler modelin farklı metin yanıtlarını puanladı. Örneğin, bir soruya verilen üç farklı cevabı doğruluk, alaka düzeyi ve üslup gibi kriterlere göre sıraladılar. Bu geri bildirimler, modele doğru ve faydalı yanıtların ne olduğunu öğretti ve insan beklentilerine uyum sağlamasını sağladı.


4. Ödül Modelinin Oluşturulması
RLHF sürecinde, insan denetçilerin verdiği puanlara dayanarak bir “ödül modeli” oluşturuldu. Bu modelin amacı, insan geri bildirimlerini taklit ederek, bir metin yanıtının kalitesini otomatik olarak değerlendirebilmekti. Bu sayede, model kendi yanıtlarını bu sanal “ödül modeli” ile karşılaştırarak kendini geliştirebildi ve insan denetçilerin devamlı müdahalesine olan ihtiyacı azaltarak, ölçeklenebilir bir öğrenme süreci yarattı.
5. Pekiştirmeli Öğrenme ile İyileştirme
ChatGPT, oluşturulan ödül modelini kullanarak pekiştirmeli öğrenme (reinforcement learning) yaptı. Bu süreçte, model yeni yanıtlar üretti ve bu yanıtlar ödül modeli tarafından puanlandı. Model, daha yüksek puan alan yanıtlar üretmeyi hedefleyerek davranışlarını optimize etti. Bu iterasyonlu süreç, modelin insan beklentilerine daha uygun, daha doğru ve daha akıcı yanıtlar üretme becerisini sürekli olarak iyileştirdi. Bu sayede, model sadece bilgili olmakla kalmayıp aynı zamanda faydalı ve kullanıcı dostu hale geldi.
6. Diyalog Odaklı Eğitim
ChatGPT’nin eğitiminde, özellikle diyalog kurabilme yeteneği üzerinde duruldu. Model, insanlarla sohbetleri, soru-cevap formatlarını ve diyalog yapılarını anlamak için özel olarak eğitildi. Bu, modelin sadece tek bir cümle değil, tutarlı ve bağlamlı konuşmalar üretebilmesini sağladı. Bu sayede, kullanıcıların karmaşık sorularını daha iyi anlayabilir ve daha akışkan bir diyalog sürdürebilir hale geldi.
7. Güvenlik ve Ahlaki Filtreleme
Eğitim sürecinde, modelin zararlı, tehlikeli veya etik olmayan içerikler üretmesini engellemek için özel önlemler alındı. Güvenlik filtreleri ve ahlaki kurallar, modelin yanıtlarını denetlemek ve potansiyel olarak zararlı çıktılardan kaçınmak üzere tasarlandı. Bu, modelin sorumlu bir şekilde kullanılmasını sağlamak için çok önemli bir aşamadır ve yapay zeka etiği konusunda atılan önemli bir adımdır.
8. Farklı Dillerdeki Verilerle Çok Dillilik
ChatGPT, sadece İngilizce değil, birçok farklı dildeki metinlerle de eğitildi. Bu çok dilli eğitim, modelin farklı dillerde soru sormayı, yanıtlamayı ve metin üretmeyi öğrenmesini sağladı. Bu sayede, küresel bir kitleye hitap edebilen ve farklı kültürlerden kullanıcıların ihtiyaçlarını karşılayabilen çok yönlü bir araç haline geldi.
9. Sürekli İyileştirme ve Güncelleme
ChatGPT’nin eğitimi tek seferlik bir süreç değildir. Model, kullanıcı etkileşimlerinden, yeni veri güncellemelerinden ve yapılan yeni geliştirmelerden sürekli olarak öğrenmeye devam ediyor. Bu sürekli iyileştirme döngüsü, modelin performansını artırıyor, hatalarını düzeltiyor ve yeni yetenekler kazanmasını sağlıyor. Bu dinamik süreç, modelin her zaman güncel kalmasını ve değişen kullanıcı beklentilerine uyum sağlamasını garantiliyor.
10. Parametre Sayısının Büyüklüğü
ChatGPT’nin yeteneklerinin temelinde, çok sayıda parametreye (milyarlarca veya trilyonlarca) sahip olması yatıyor. Bu parametreler, modelin öğrenme sürecinde edindiği bilgileri ve kalıpları depoladığı sinir ağı bağlantılarıdır. Parametre sayısının büyüklüğü, modelin karmaşık ilişkileri anlamasına ve son derece çeşitli konularda tutarlı ve doğru yanıtlar vermesine olanak tanır. Bu yapısal büyüklük, modelin sofistike bir dil anlayışına sahip olmasını sağlar.





 Sistemi Neyin Nesi? Hangisini Önce Geliştirmeli?")











